AI研究論文速讀 | 比較多語言LLM Prompting效益●
ChatGPT 我地用得多 但你有冇都曾經諗過
用中文prompt 問佢野 vs 用英文prompt問佢野 佢既準確性會有幾大分別?
//
一路以黎我都比較執著用英文問LLM 野, 然後叫佢「response in Traditional Chinese」
因為我主觀覺得,用英文問 先最直接觸及到佢訓練知識源 , aka 最準
為左證實呢樣野, 我搵左D 有關呢方面既LLM research paper 黎睇
//
Spoiler / tl;dr :
- 英文 vs 中文 performance 的確存在差距,但並唔係十分大,一般用家可以不用特別理會 而且呢篇係4月publish,即係未有4o,
模型能力愈出愈強, 差距必然會愈黎愈細 所以養成使用習慣,比追求高精確率更重要
//
- 論文只包含ChatGPT, Gemini 同其他幾個open source model 無 Claude 模型,建議先相信自己使用體驗同直覺去使用。 我自己個人感覺Claude 用起上黎就算用中文問都冇咩大分別
但商用,開發,或者對專業度,精確度有要求既話,建議首選英文input
//
以下技術向內容 for 有興趣朋友參考 :
呢個係Microsoft research team 做, 有關不同LLM 模型對於不同語言input / output 既performance benchmarking research 語言
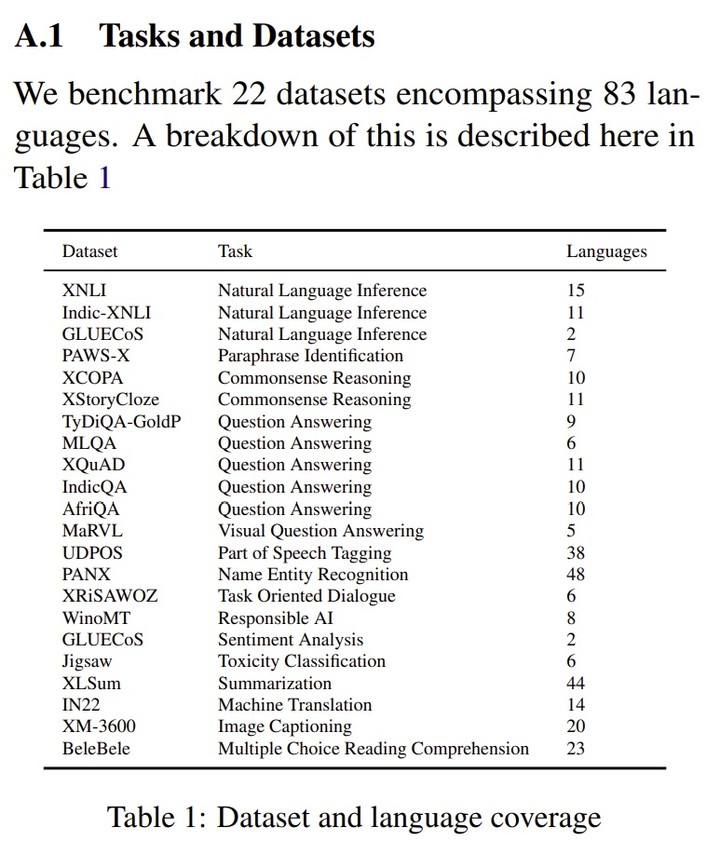
sample : 有83種語言, 對應唔同類型既Dataset , 總共 22個
LLM sample : 下圖一 個12個
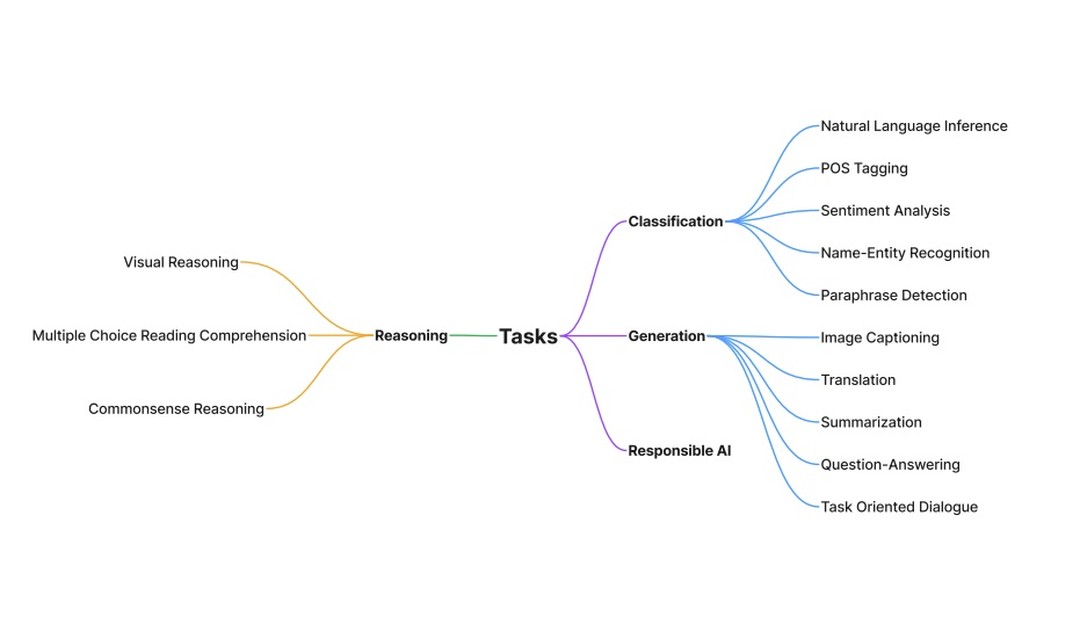
測試面向cover 唔同場境,例如translation, summarization, 情感分析, 圖像分析之類, 下圖二
 !
!
//
Result takeaways :
-
OpenAI 系列係對應不同語言場境performance 最好, 可能因為pre-train dataset 夠足,但基本上都係英文壟斷晒第一位,偶而有一兩個evaluation 意大利文同法文跟到
-
(佢中文只分簡體繁,廣東話冇被考慮在內)
-
比起拉丁語家族,中文 (Sino-Tibetan) 係多個測試dataset類別,都被歸類為low scores candidates , 尤其 XM-3600 dataset 測vision 能力時 , 分數同日文 / 泰文一樣都係最低分組。雖然分數差別都係大概十分咁上下
-
較小型開源模型清一色以英文為主導,完全無得比
-
Research team 測試用既prompt 值得參考 (You are a helpful NLP assistant solving XXXX)
-
我個人覺得如果佢以而家呢個model market , i.e. 包埋GPT4o , Sonnet 3.5 , Gemini Pro 1.5 1M , Llama 3 之類再做一次 , 參考性會再大D
//
所以我個人黎講
如果唔係快問快答,而係有structure 既prompts 我都係會傾向用返英文同LLM 溝通
不過用LLM最緊要原則都係
按返大家自己既使用習慣,同實際需求出發
//